Property Research Microservice
A cost-optimized microservice concept that correlates public geographic data to help resolve locations with a PostGIS-backed pipeline.
Overview
This project is a microservice-style system intended to correlate public data points across geography (and related identifiers) to support location resolution and research workflows. The core idea is a PostGIS-backed geographic resolution layer paired with automated ingestion pipelines, aiming to stay cost-efficient by leaning on free-tier services where possible.
Current status: in progress. The focus is on designing the ingestion + resolution approach and the overall architecture before locking down implementation details and full dataset coverage.
Media
Add screenshots / diagrams / sample query outputs here. Put files in frontend/assets/.
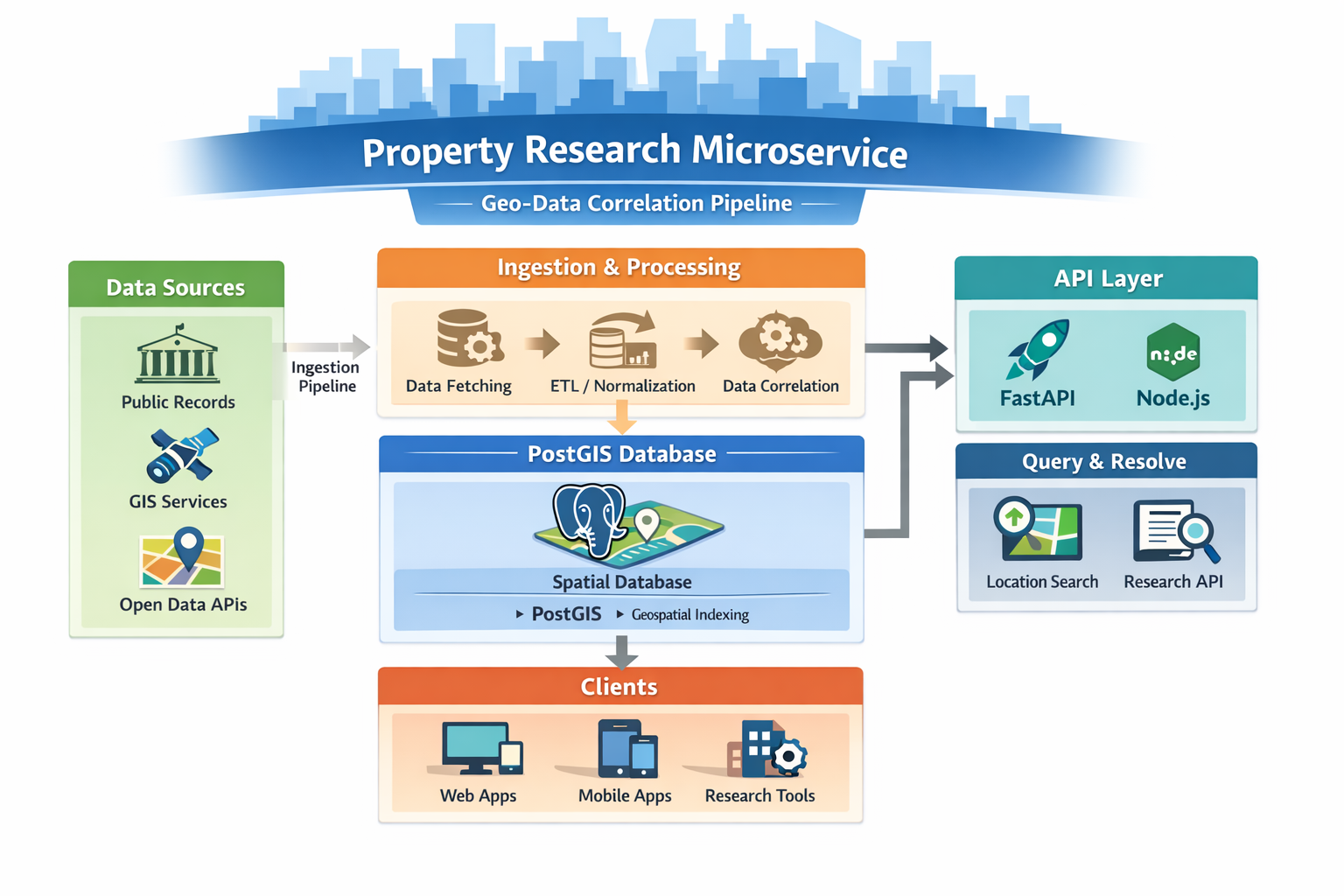
Tech Stack
Key Features
- PostGIS-backed geographic resolution using spatial queries to map and relate locations
- Automated ingestion pipeline (planned/in progress) to pull and normalize public geographic datasets
- Correlation layer (planned/in progress) to link data points into a consistent research-ready structure
- Cost-optimized architecture goal designed around free-tier or low-cost infrastructure choices
My Contribution
- Defined the system concept and the “microservice” approach for geographic resolution + data correlation
- Chose the database strategy: PostGIS for spatial indexing and resolution logic
- Planned the ingestion workflow: how public datasets get pulled, normalized, and stored for querying
- Designed the early API direction (FastAPI / Node.js) for exposing resolution and lookup endpoints
Results
- Clear architecture direction: PostGIS-centered resolution with ingestion + API layers
- Technical growth: spatial database thinking (indexes, geometry queries, resolution strategies)
- Cost discipline: designing constraints-first around free-tier/low-cost services
- Next steps: implement ingestion jobs, finalize schema, add initial datasets, and stand up stable API endpoints